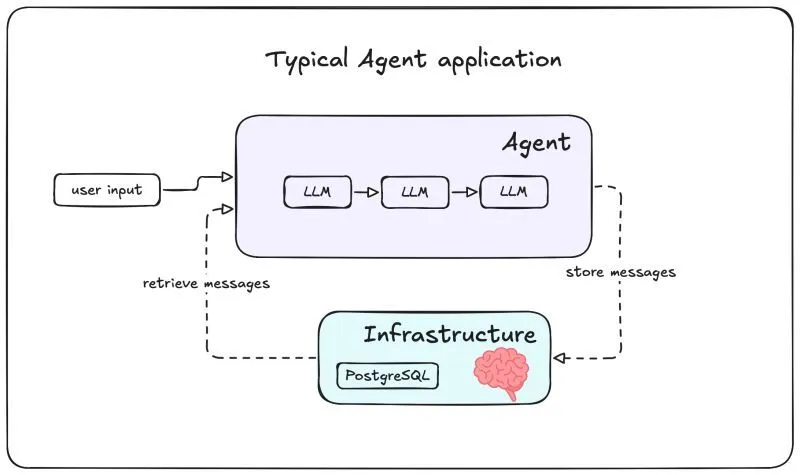
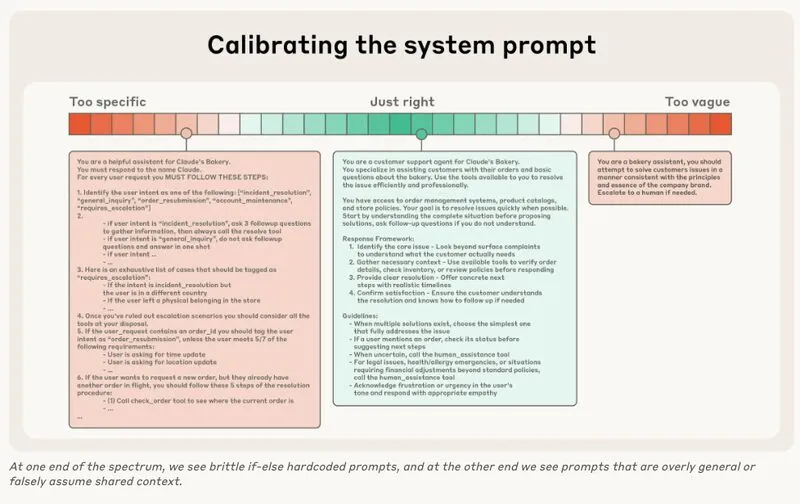
El problema: Cold Starts que matan la experiencia de usuario
Si has desplegado modelos de machine learning en serverless, conoces este escenario: implementas Sentence Transformers para traducción o detección de idiomas, creas tu imagen Docker, la despliegas para controlar costes, y descubres que tu imagen de 4GB tarda tres minutos en arrancar.
Este problema afecta a equipos globalmente. Las arquitecturas serverless eficientes chocan con modelos de IA que requieren tiempos de inicialización incompatibles con experiencias en tiempo real.
Por qué serverless y modelos de IA no siempre funcionan
Serverless funciona perfectamente para funciones ligeras. El problema surge con modelos de deep learning que requieren cargar pesos del modelo, inicializar PyTorch o TensorFlow, y preparar estructuras de datos complejas.
Factores críticos: Los transformers pesan varios gigabytes. Los contenedores serverless sufren cold starts constantes. Las dependencias de deep learning añaden tiempo significativo. La inicialización requiere recursos computacionales considerables.
Tres minutos son aceptables para procesos batch, pero inaceptables cuando usuarios esperan respuesta inmediata.
La Solución: Desacoplamiento con microservicios especializados
La respuesta está en desacoplar y crear microservicios especializados.
Crea un microservicio dedicado para inferencias de IA en un servidor tradicional siempre activo. Este servidor mantiene modelos cargados en memoria, eliminando cold starts. Tus servicios serverless consumen este microservicio vía HTTP/REST o gRPC, obteniendo respuestas instantáneas.
Ventajas: El microservicio arranca una vez y mantiene modelos en memoria permanentemente. Las funciones serverless permanecen ligeras. Escalas horizontalmente sin afectar tu arquitectura. Reduces costes evitando arranques repetidos. Centralizas gestión de modelos.
Implementación en dos componentes
Microservicio de inferencia persistente: Despliega en AWS EC2, Google Compute Engine o Azure VM. Implementa FastAPI o Flask exponiendo endpoints. Carga modelos durante el arranque. Implementa health checks y reinicio automático.
Funciones serverless como orquestadores: Lambda, Cloud Functions o Azure Functions actúan como capa de lógica. Reciben solicitudes, validan, llaman al microservicio, procesan respuestas y devuelven resultados.
Cuándo aplicar esta arquitectura
Usa microservicios persistentes cuando: Necesitas respuestas en tiempo real (menos de 1-2 segundos). Tienes volumen constante de solicitudes. Trabajas con modelos grandes (más de 1GB). Requieres procesamiento concurrente con baja latencia.
Alternativas válidas: Para batch sin requisitos de latencia, serverless funciona. Lambda soporta imágenes hasta 10GB. Para modelos pequeños (menos de 500MB), serverless puro es viable. AWS SageMaker o Google AI Platform ofrecen soluciones managed.
Optimización de costes
Implementa auto-scaling reduciendo capacidad en horas valle. Usa instancias spot aceptando interrupciones. Agrupa múltiples modelos si comparten dependencias. Implementa caché para solicitudes frecuentes. Considera instancias reservadas si tu tráfico es predecible.
Compara el coste de servidor persistente versus cold starts frecuentes, timeouts y experiencia degradada.
Conclusión: Pragmatismo arquitectónico
Desplegar modelos de IA requiere pragmatismo. Serverless es poderoso pero no universal.
La clave está en reconocer cuándo desacoplar componentes pesados de IA en microservicios persistentes. Esta arquitectura híbrida mantiene eficiencia serverless para lógica de negocio y baja latencia de servidores dedicados para inferencia.
Si trabajas con Sentence Transformers o cualquier modelo con tiempos de inicialización significativos, considera esta arquitectura. Tu experiencia de usuario te lo agradecerá.
¿Necesitas diseñar una arquitectura híbrida con baja latencia para tus modelos? Contáctanos y optimiza tu despliegue de IA.